1. vm VirtualBox에서 서버 세 개 가동
- login은 하지 않기!
2. MobaXterm에서 CentOS 서버 접속하기
* putty 대신 Mobaxterm 사용예정
여러 개의 서버 접속 시 보다 간편, 탭 구분 가능 등 사용하기 편리함
1) SSH로 접속하기
User session- New session 눌러 Server01, Server02, Server03 세 개 만들기
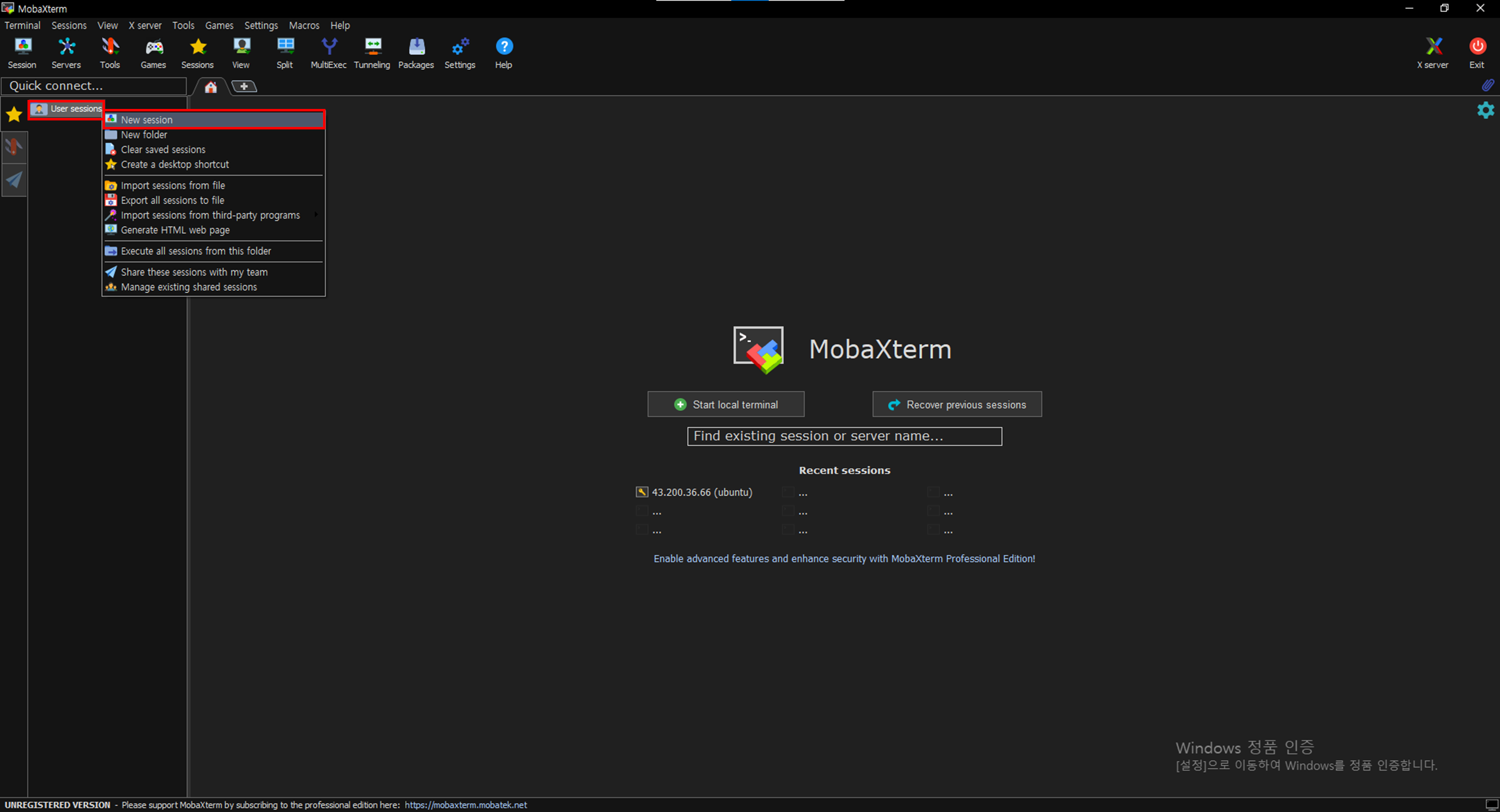
*Server01
Remote host: 192.168.101 Session name: Server01 Comments: 192.168.101
*Server02
Remote host: 192.168.102 Session name: Server01 Comments: 192.168.102
*Server03
Remote host: 192.168.103 Session name: Server01 Comments: 192.168.103
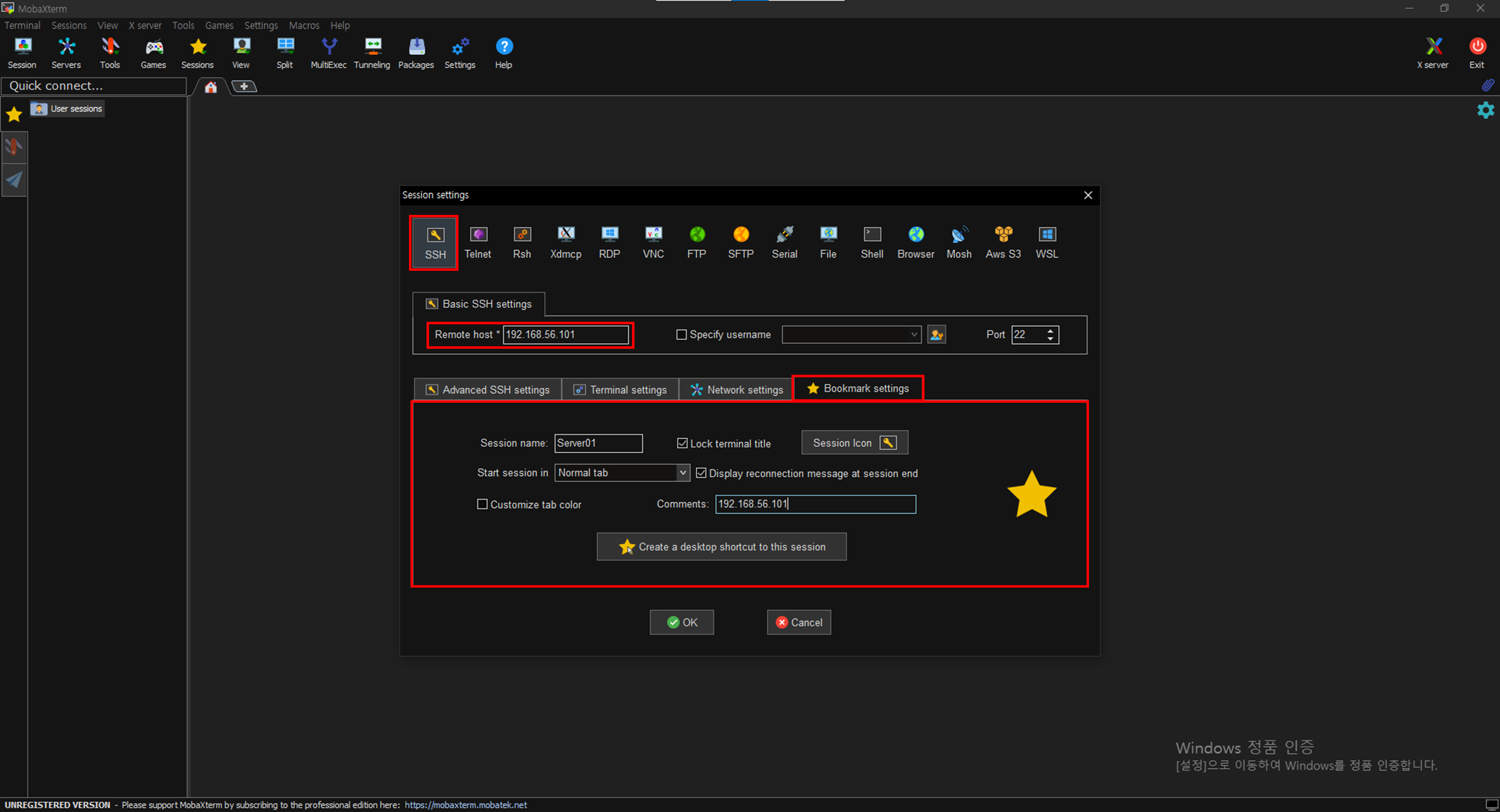
위와 같은 방식으로 세 개 생성 완료

2) 클라우데라 매니저 설치
***클라우데라 버전 7***
Cloudera (CDH) Installl Guide
클러스터 호스트 요구 사항
① 루트 사용자 계정 또는 암호 없는 sudo 권한이 있는 계정을 사용하여 Cloudera Manager Server 호스트에 로그인할 수 있어야 한다.
=> server 세 개 같은 비밀번호 설정해두었음
② Cloudera Manager Server 호스트는 모든 호스트에 대해 동일한 포트에서 균일한 SSH 액세스 권한을 가져야 한다.
=> port 번호 7108
③ 모든 호스트는 운영 체제용 표준 패키지 리포지토리와 archive.cloudera.com 또는 필수 설치 파일이 있는 로컬 리포지토리에 액세스할 수 있어야 한다.
④ 설치 프로그램을 실행하기 전에 SELinux를 비활성화하거나 허용 모드로 설정해야 한다.
***세 군데에다 동일한 코드를 동시에 넣어줄 때도 하나의 서버에만 넣어야 하는 코드도 있으니 주의하기!!! ***
*** 특정 언급 없으면 server01, 02, 03 모두 코드 작성하기 ***
01. 세션 세 개 로그인하기
- 매번 로그인하기 귀찮으니 저장해두자!

02. 네트워크 이름 구성
# Configure Network Names
$ hostname
$ cat /etc/hosts
03. 방화벽 비활성화
# Disabling the Firewall
$ sudo iptables-save > ~/firewall.rules
$ sudo systemctl stop firewalld
04. SELinux 세팅하기
# Setting SELinux mode (Security-Enhanced Linux)
$ getenforce
>>> disabled
$ vi /etc/selinux/config
=> SELINUX=permissive 변경
$ cat /etc/sysconfig/selinux
$ setenforce 0
$ setenforce 1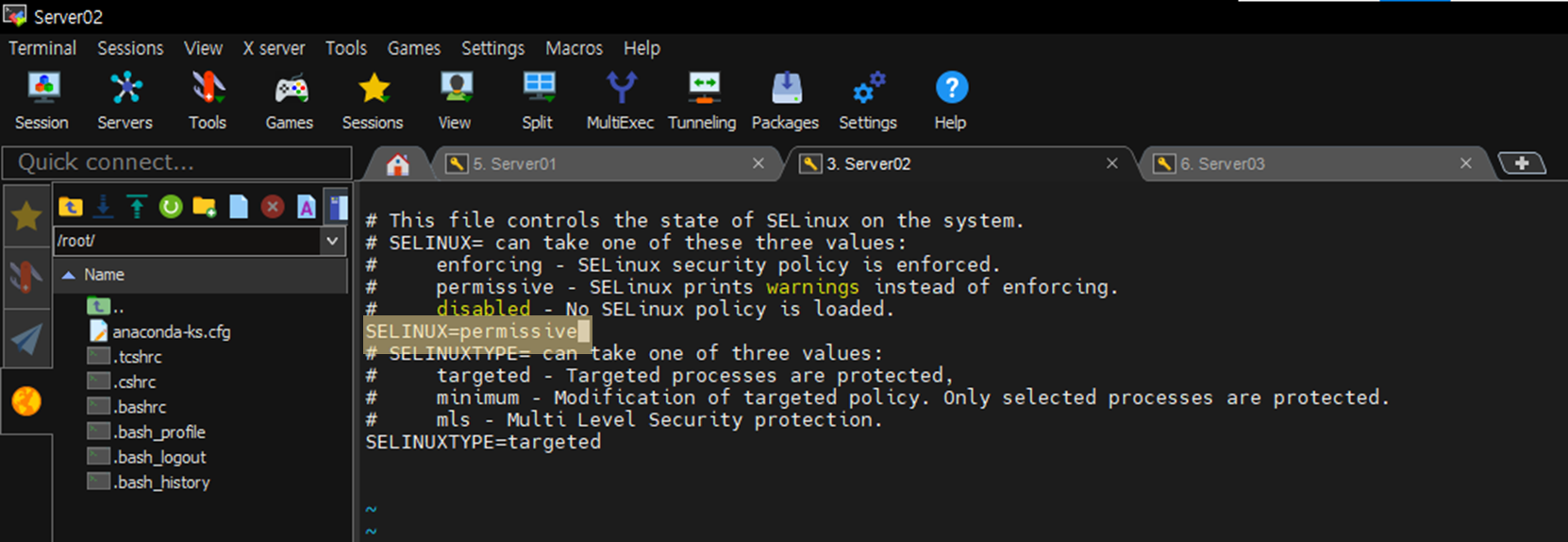

- Server01(Master)
- Server02(Slave), Server03(Slave)
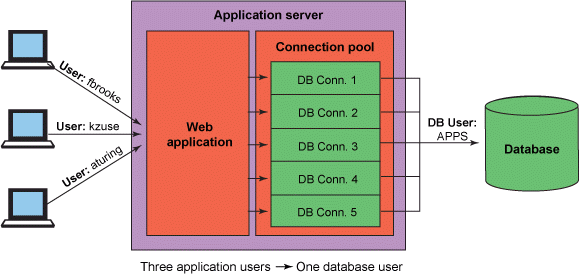
[그림 1] 커넥션 풀 ( 출처: IBM’s article https://www.ibm.com/developerworks/data/library/techarticle/dm-1105fivemethods/index.html )
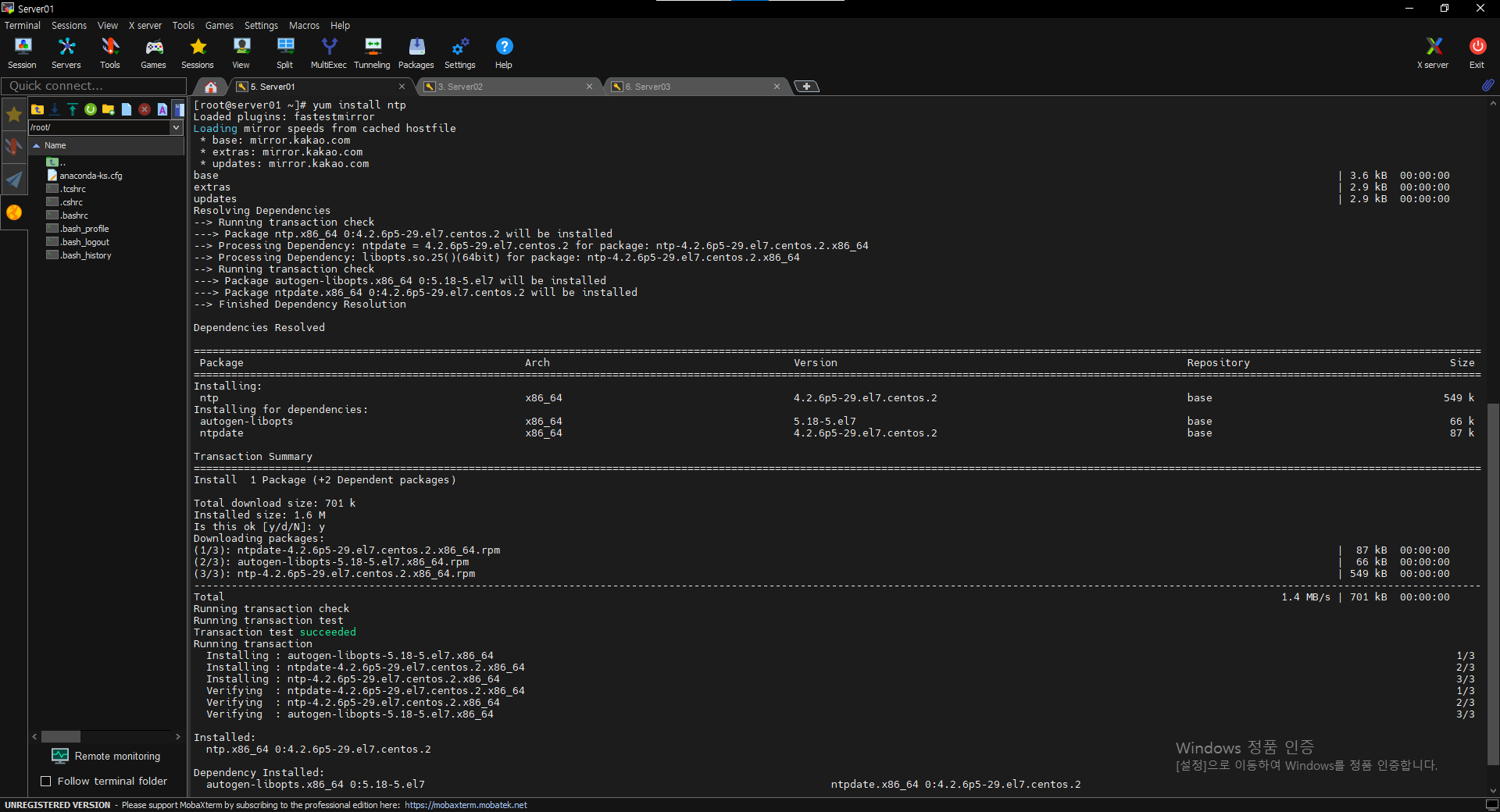
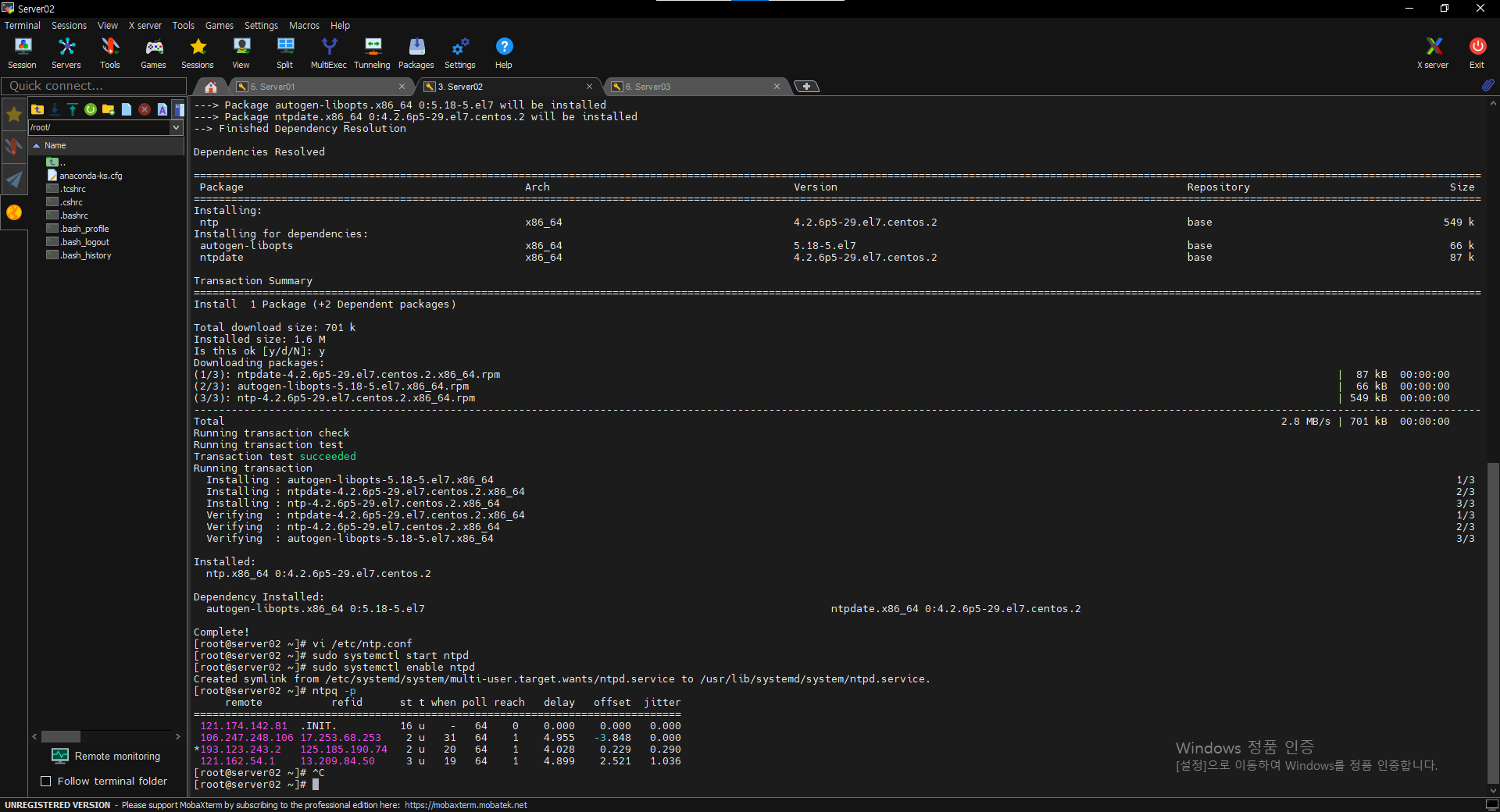
Enable an NTP Service
$ yum install ntp
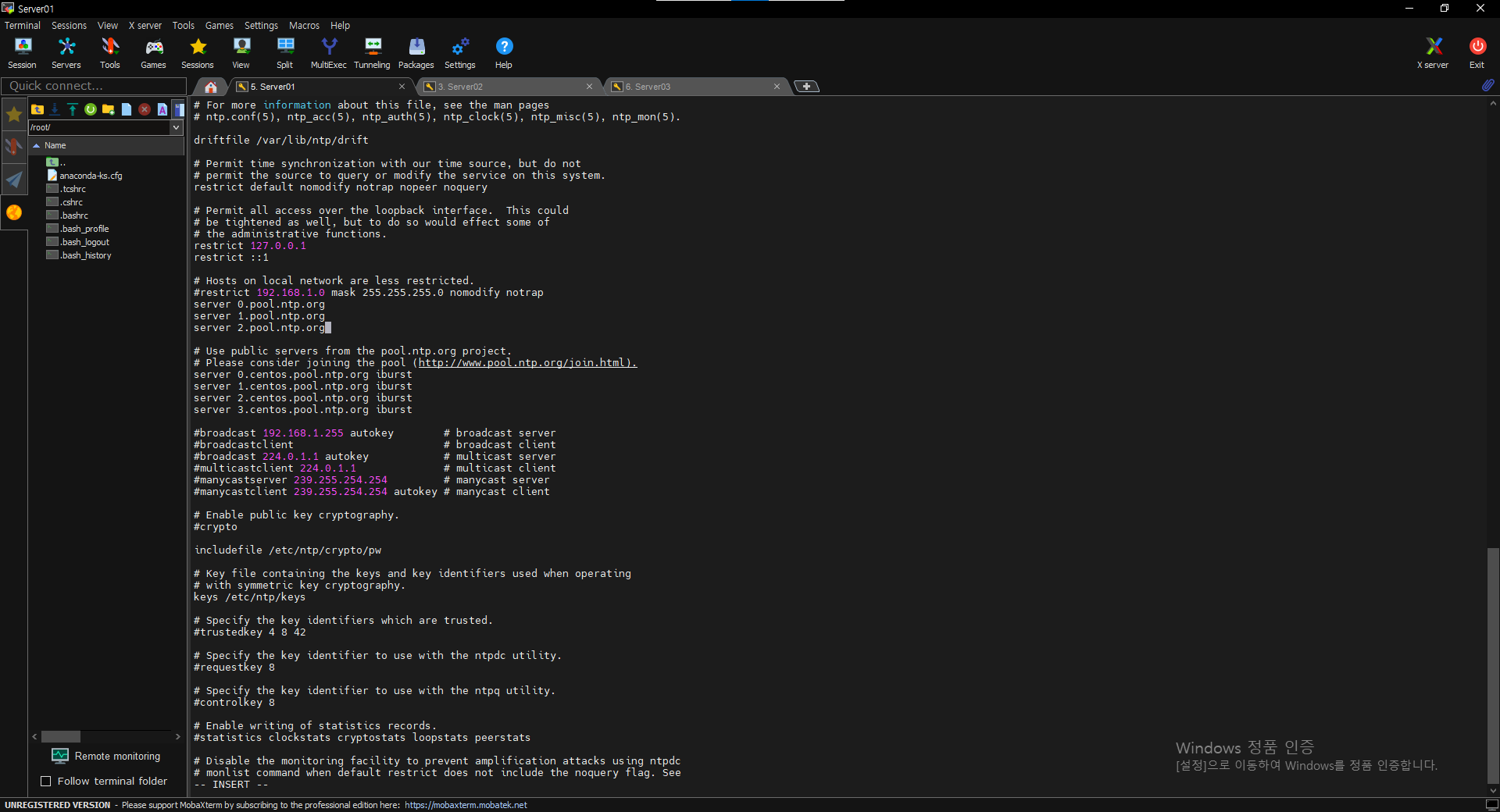
$ vi /etc/ntp.conf
=> server 0.pool.ntp.org
=> server 1.pool.ntp.org
=> server 2.pool.ntp.org
*** 노드 구별(Master)
=> server 127.127.1.0
=> fudge 127.127.1.0
=> stratum 0
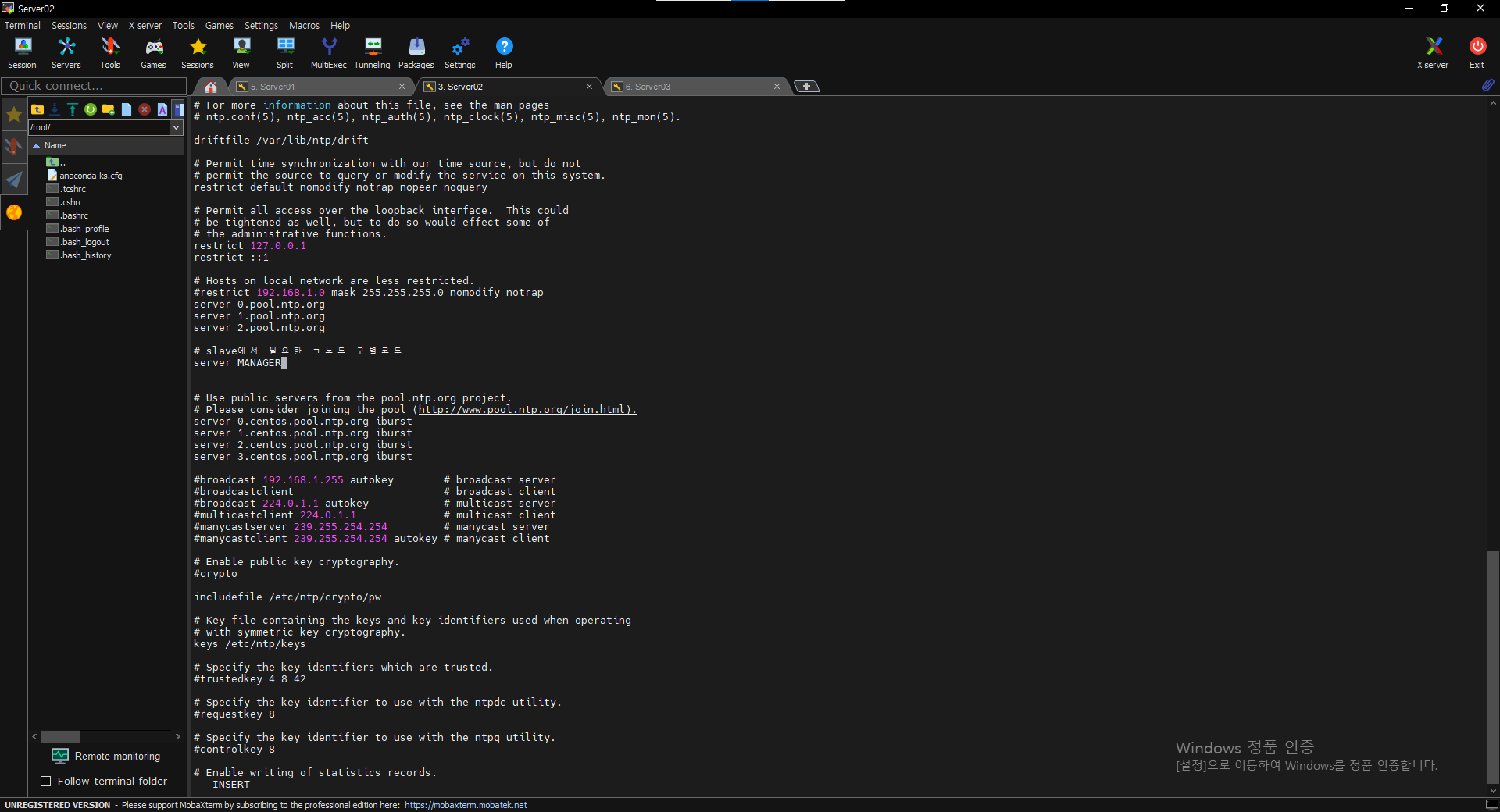
*** 노드 구별(Slave)
=> server MANAGER
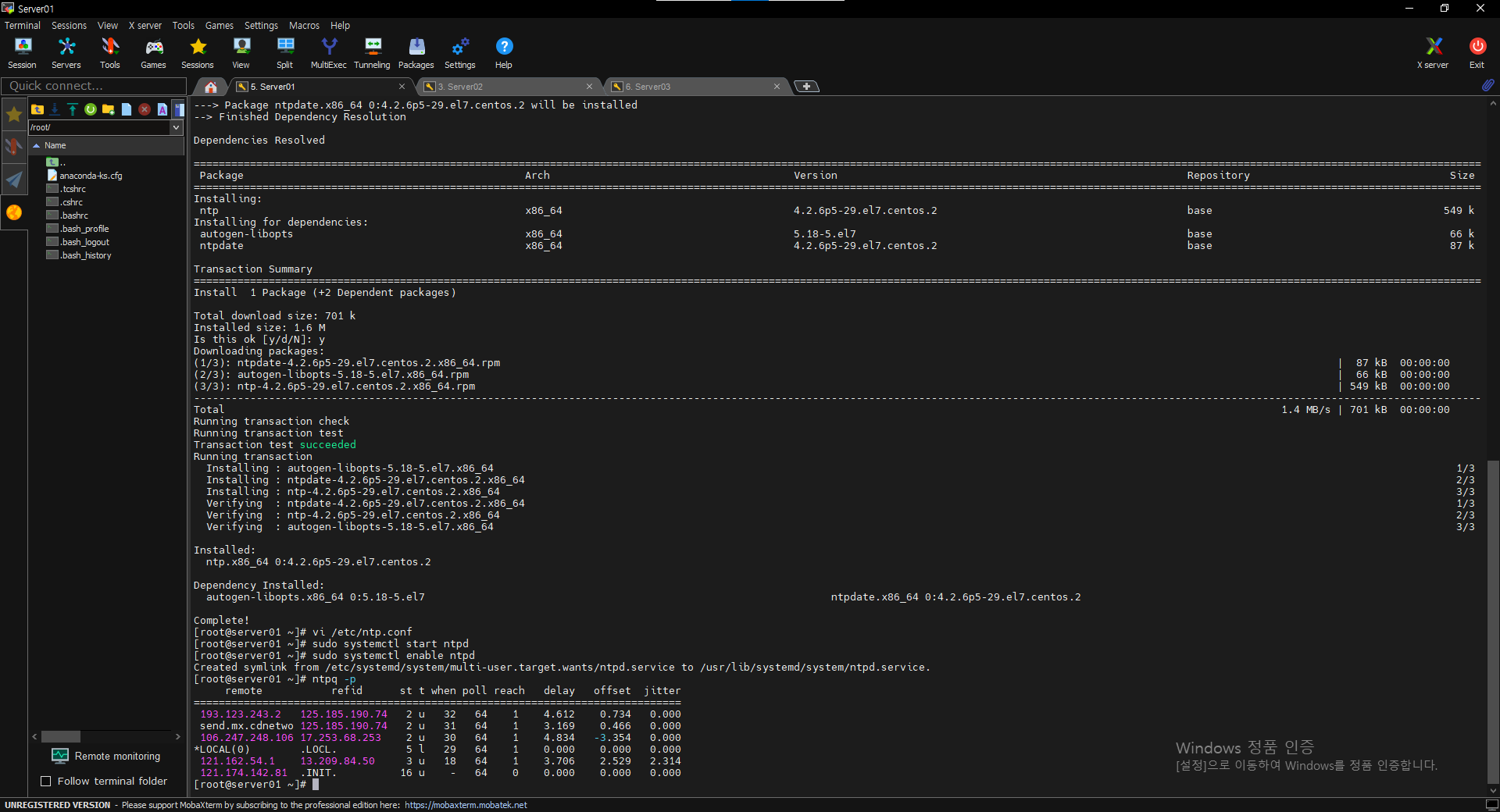
$ sudo systemctl start ntpd
$ sudo systemctl enable ntpd
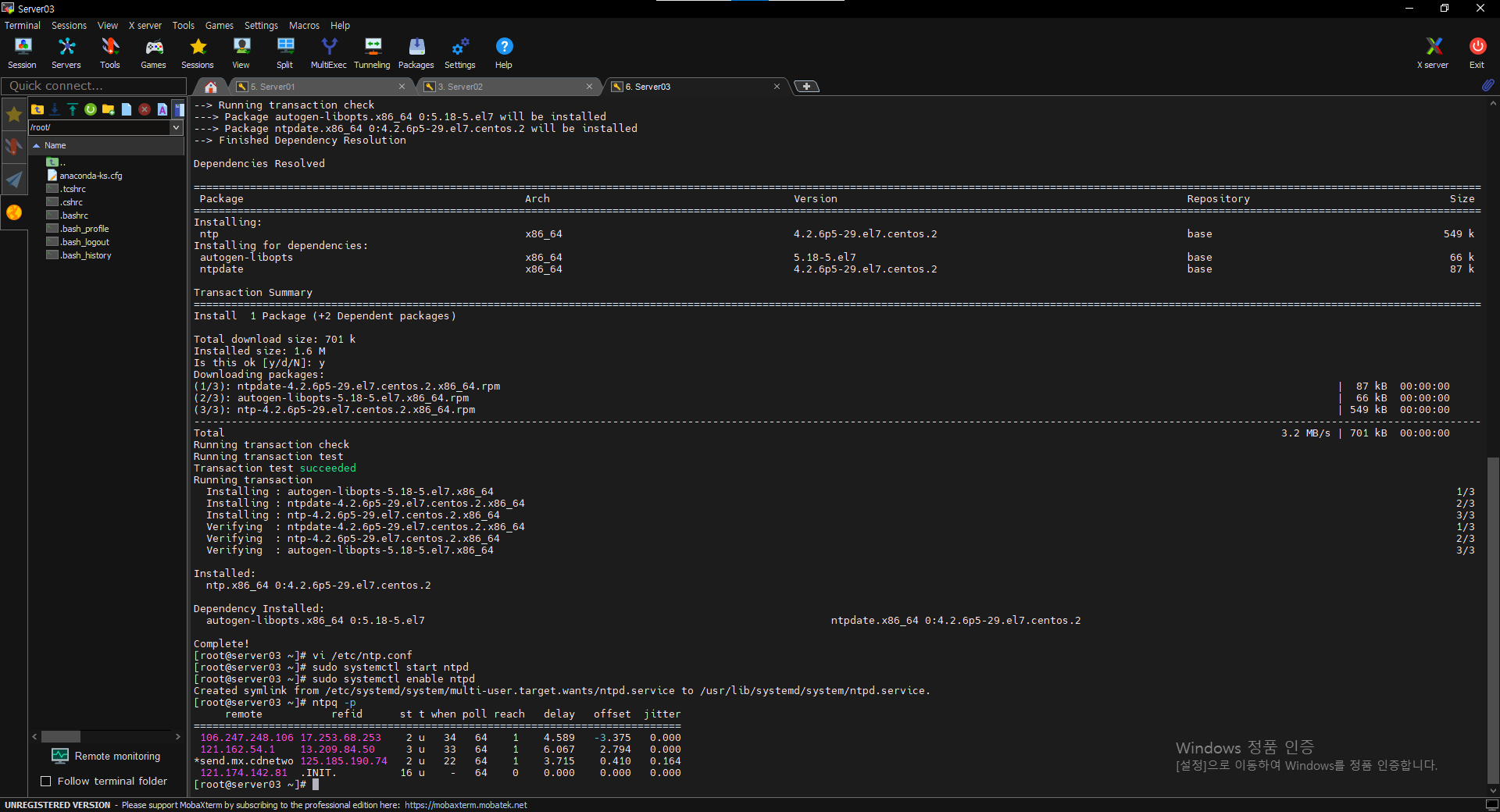
$ ntpq -p
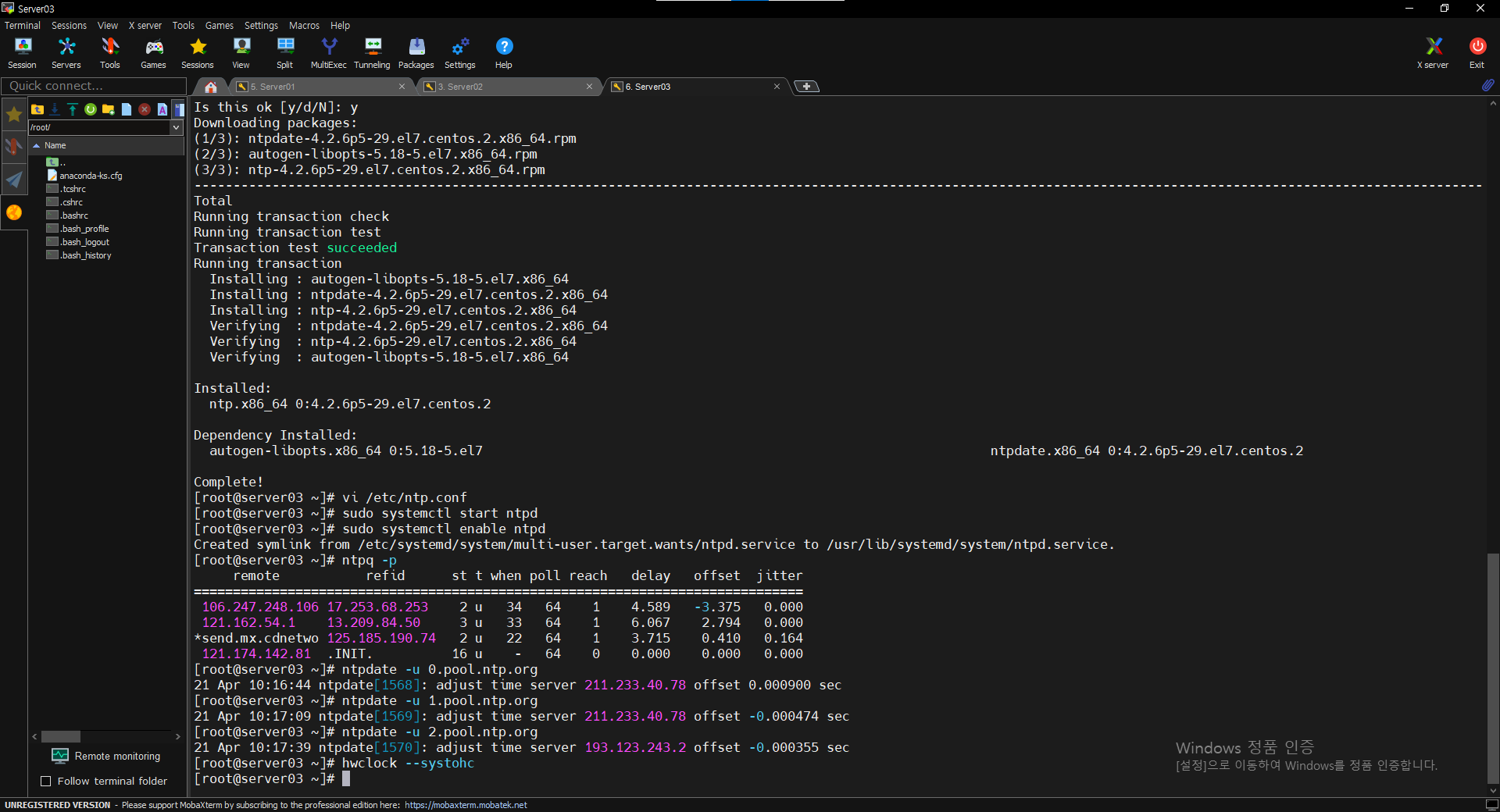
$ ntpdate -u 0.pool.ntp.org
$ ntpdate -u 1.pool.ntp.org
$ ntpdate -u 2.pool.ntp.org
$ hwclock --systohc




클라우데라 설치조건
1. python 설치
파이썬 설치되어있지만 클라우데라가 해당 파이썬을 찾지 못 해
2. 자바 필요(JDK)
클라우데라6. 대는 직접 설치해야 하는데
7.0은 클라우데라 설치할 때 자바 알아서 설치해줌
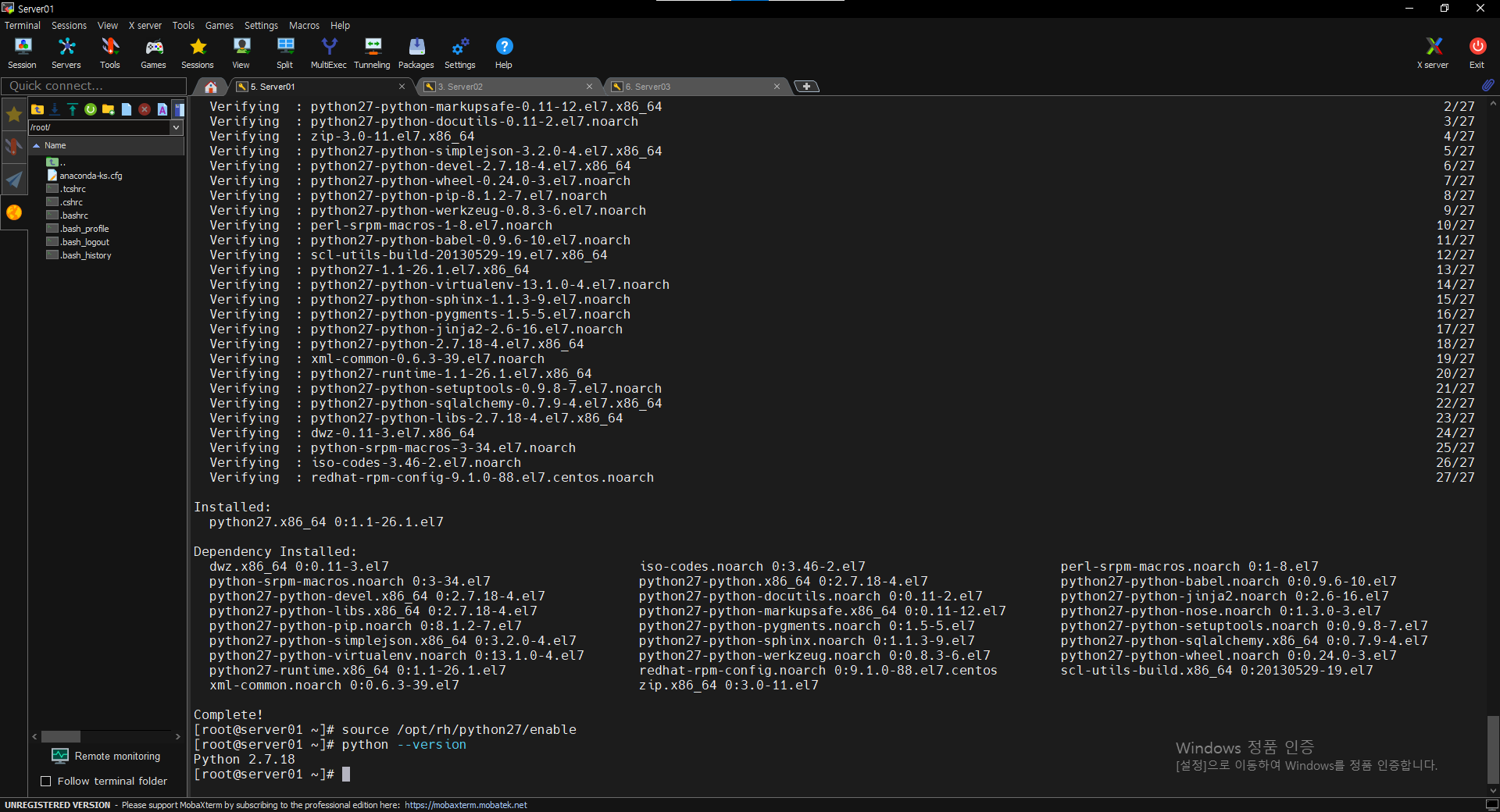
(RHEL 6 Compatible Only) Install Python 2.7 on Hue Hosts
$ sudo yum install centos-release-scl
$ sudo yum install scl-utils
$ sudo yum install python27
$ source /opt/rh/python27/enable
$ python --version
파이썬 현재 두 가지야 나는 어떤 파이썬을 쓰겠다 지정해주는 거
Cloudera 설치
Installing Cloudera Manager, CDH, and Managed Services
$ wget https://archive.cloudera.com/cm7/7.4.4/cloudera-manager-installer.bin
$ chmod u+x cloudera-manager-installer.bin
$ sudo ./cloudera-manager-installer.bin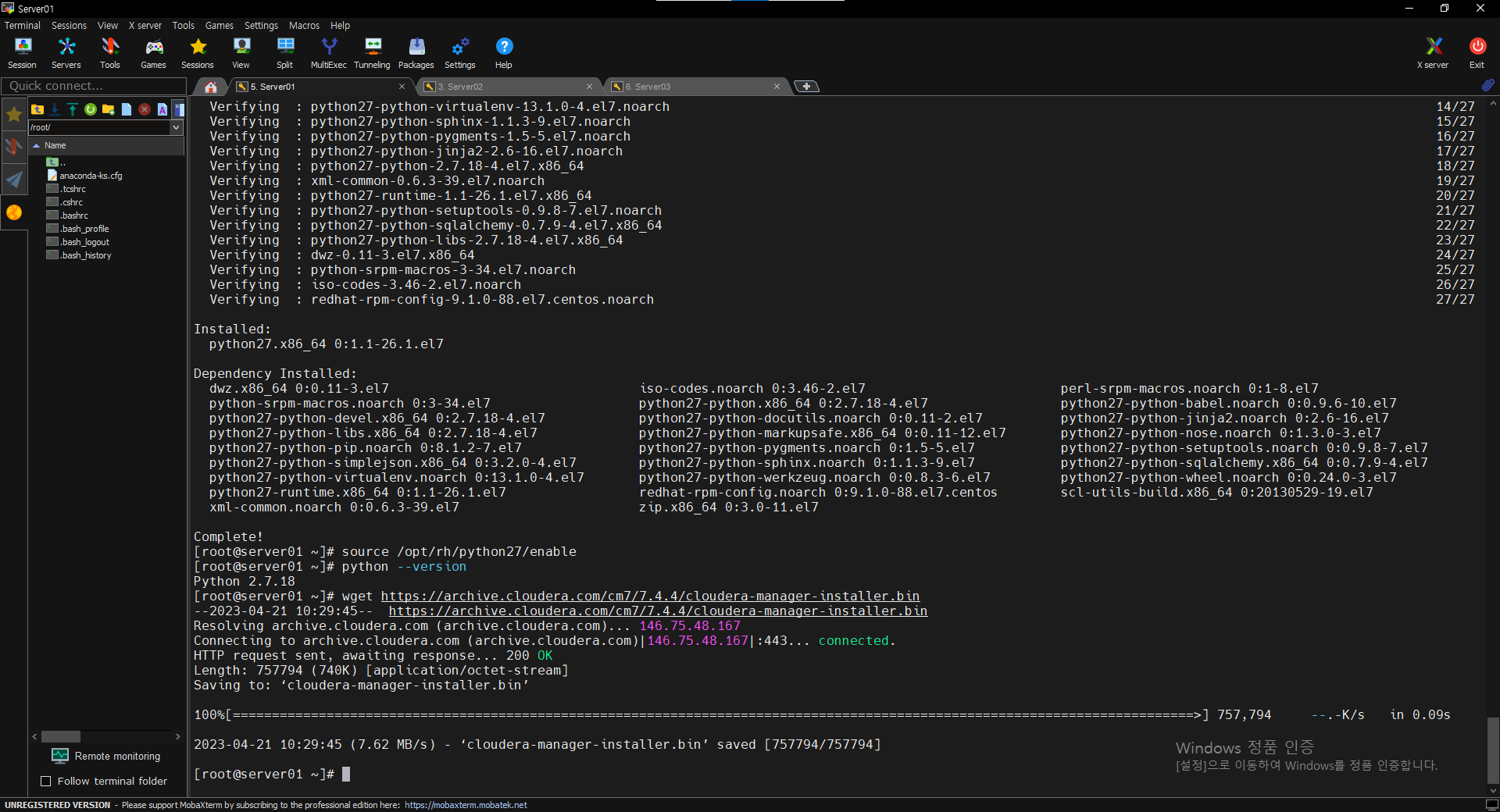



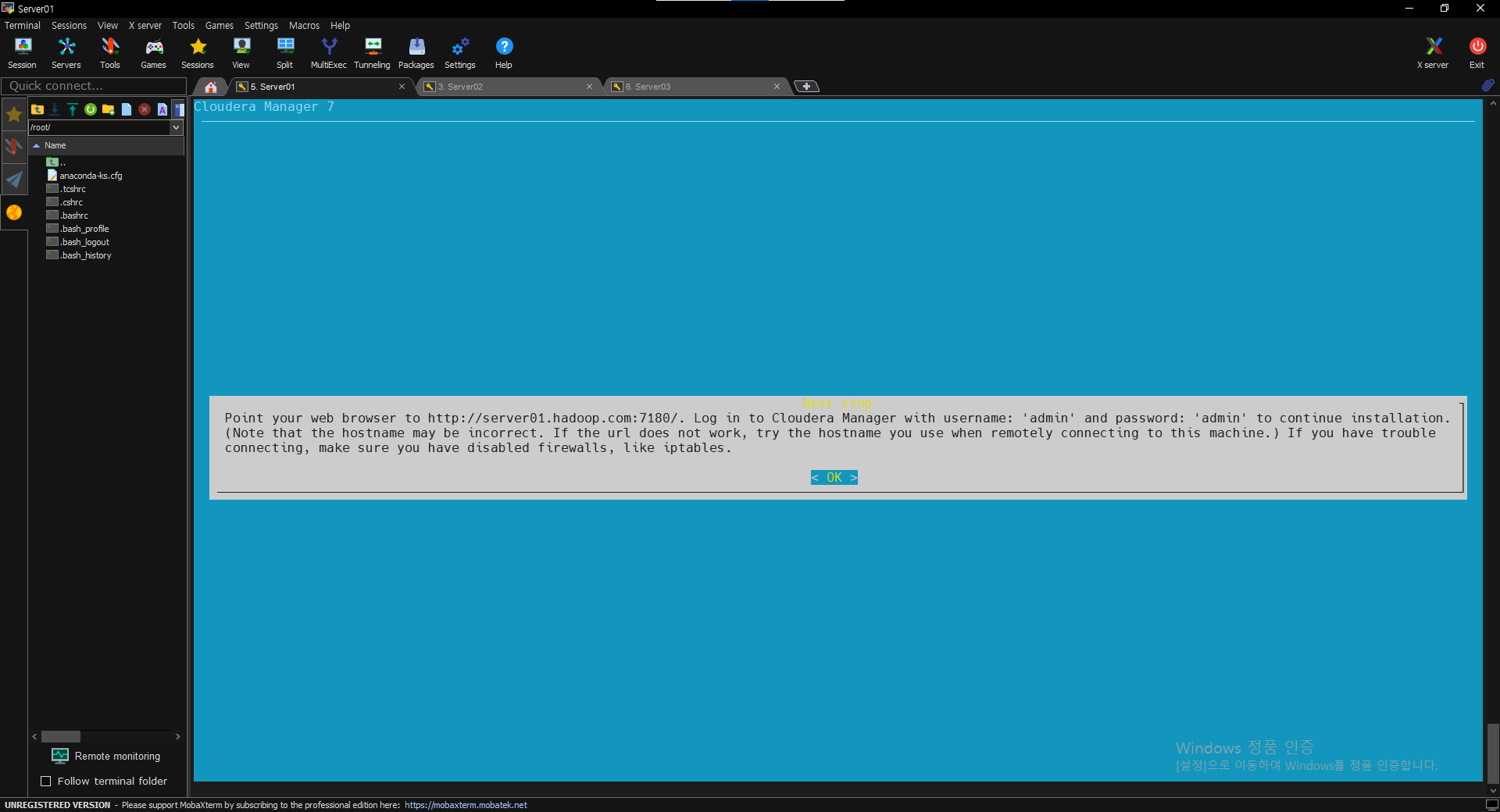
$ ssh-keygen -t rsa
계속 ENTER
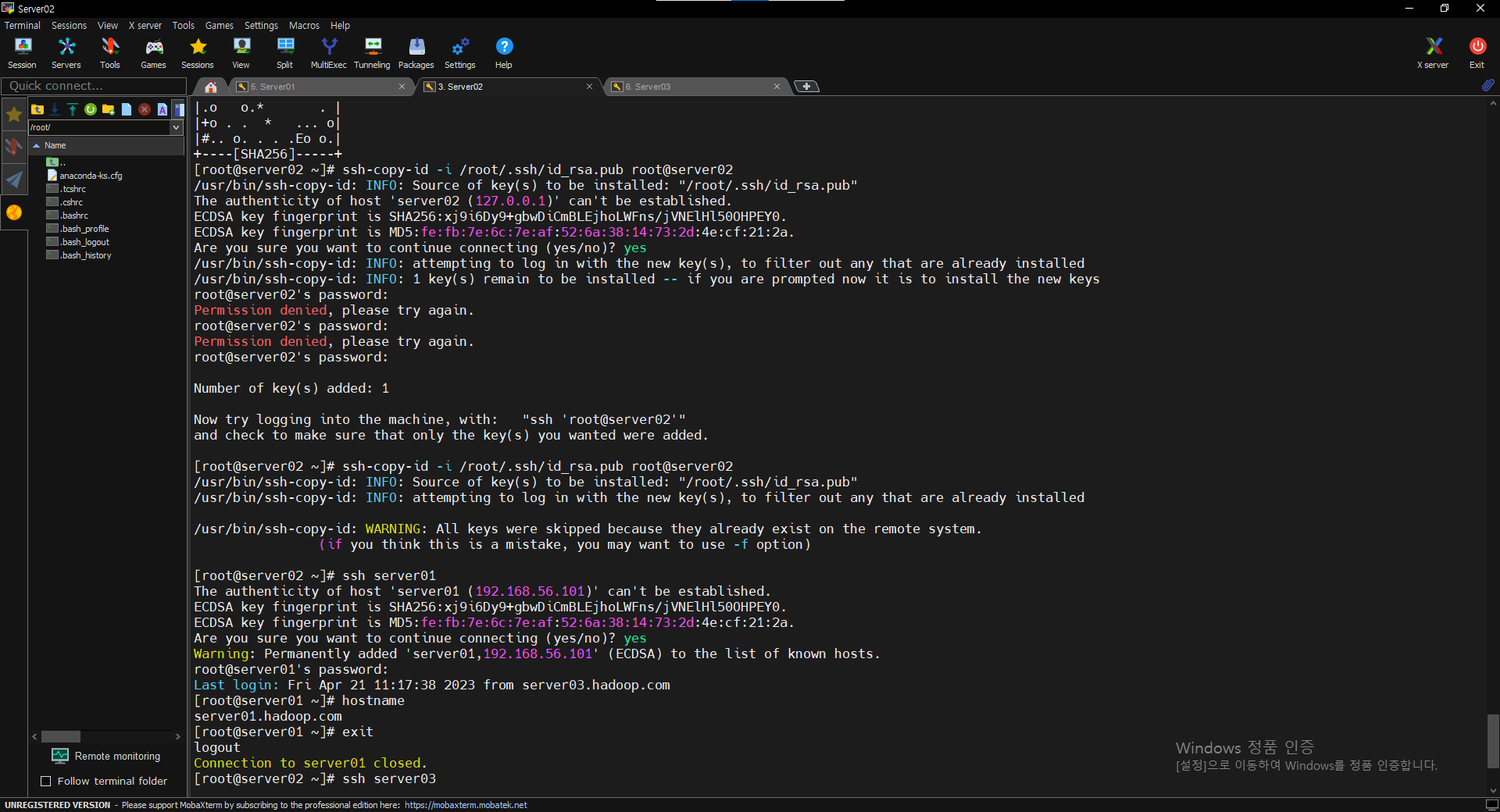
$ ssh-copy-id -i /root/.ssh/id_rsa.pub bigdata@server01
비밀번호 : bigdata
$ ssh-copy-id -i /root/.ssh/id_rsa.pub bigdata@server02
비밀번호 : bigdata
$ ssh-copy-id -i /root/.ssh/id_rsa.pub bigdata@server03
비밀번호 : bigdata
$ ssh server02
$ hostname
$ exit
$ ssh server03
$ hostname
$ exitserver01에서 server02, server03접속해보기

** 노드 구별(M)
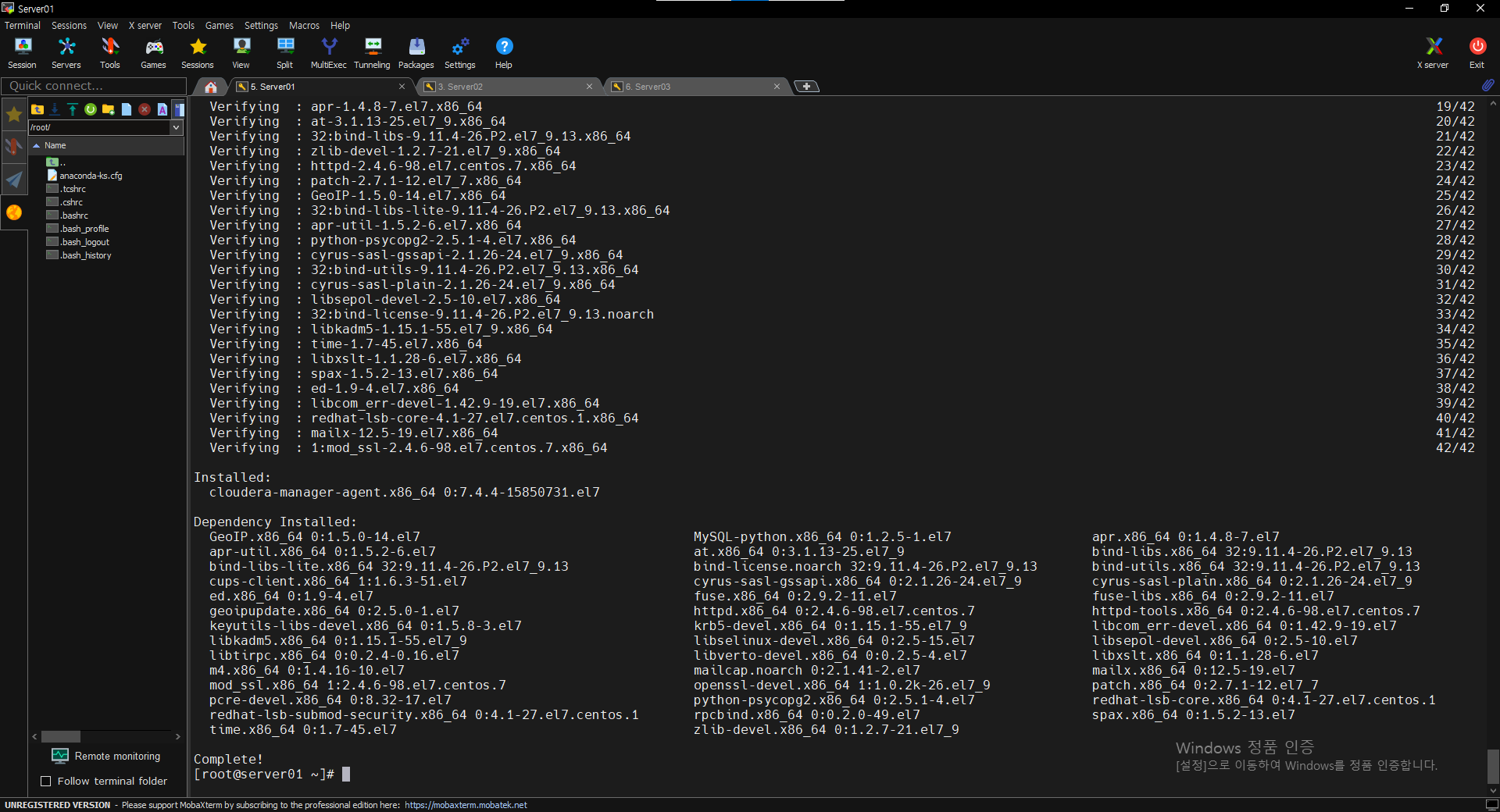
$ sudo yum install cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
$ service cloudera-scm-server-db status
$ sudo service cloudera-scm-server start
$ netstat -nap | grep 7180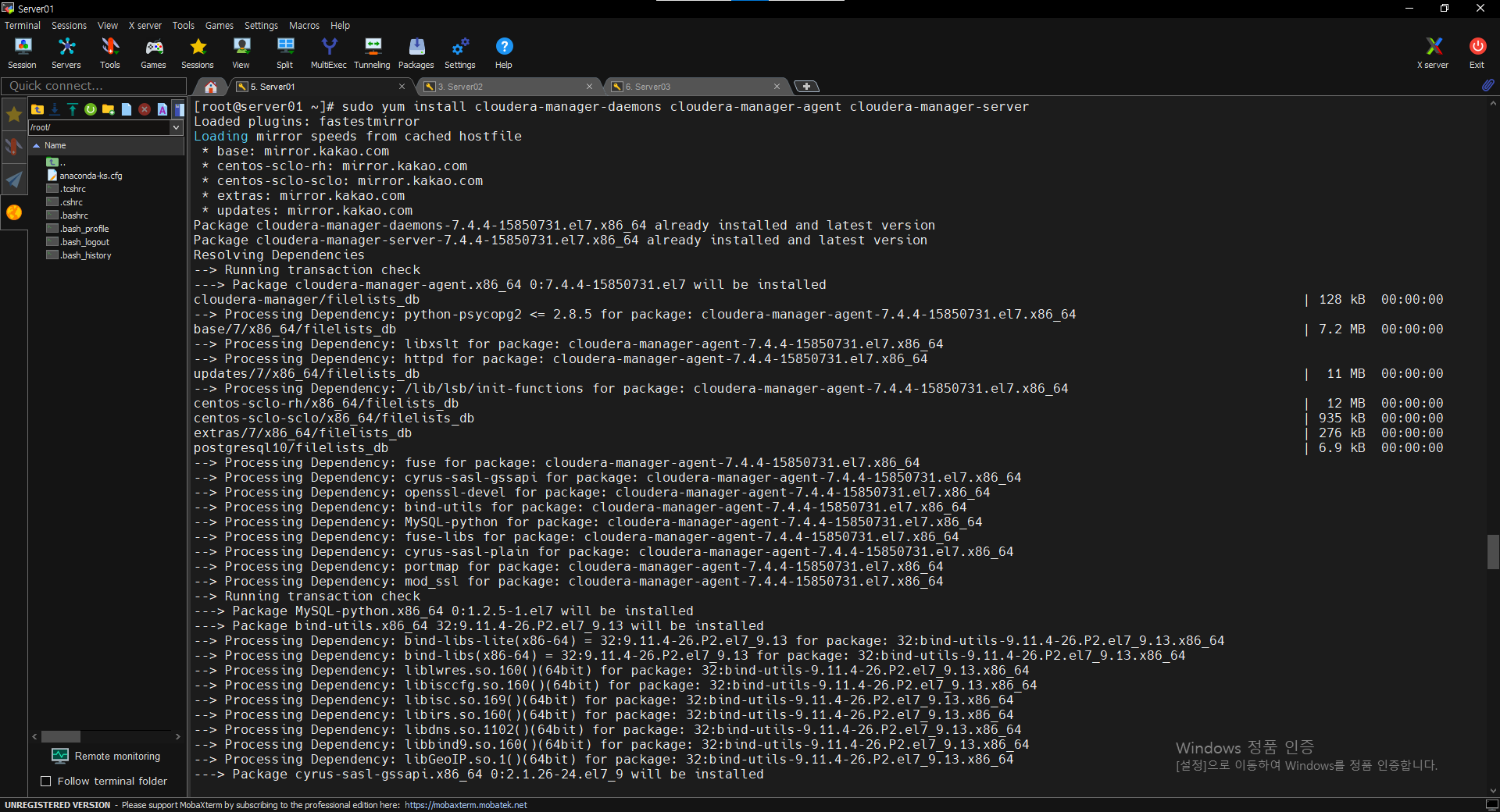

** 노드 구별(S)
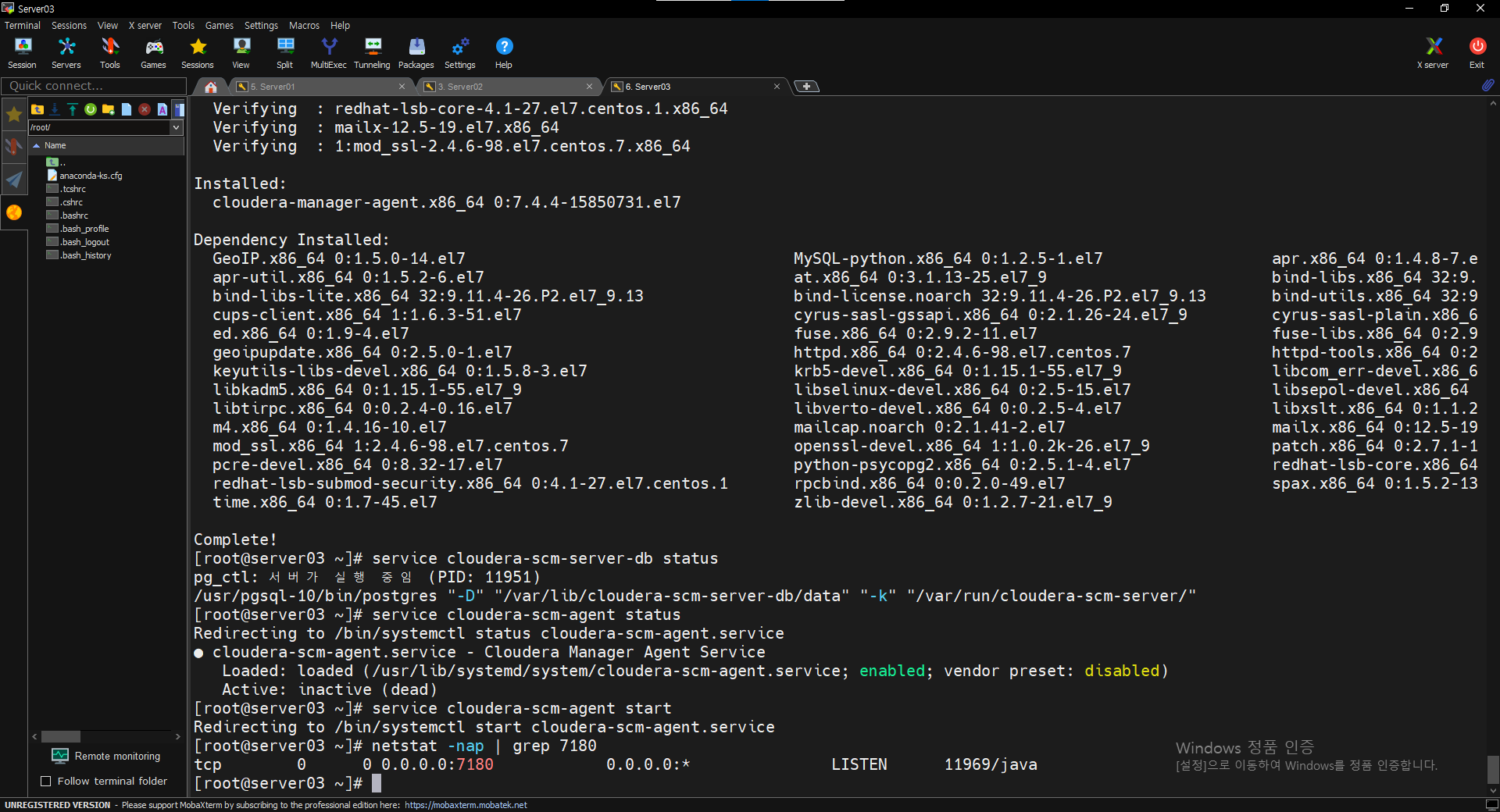
$ sudo yum install cloudera-manager-daemons cloudera-manager-agent
$ service cloudera-scm-server-db status
$ service cloudera-scm-agent status
$ service cloudera-scm-agent start
$ netstat -nap | grep 7180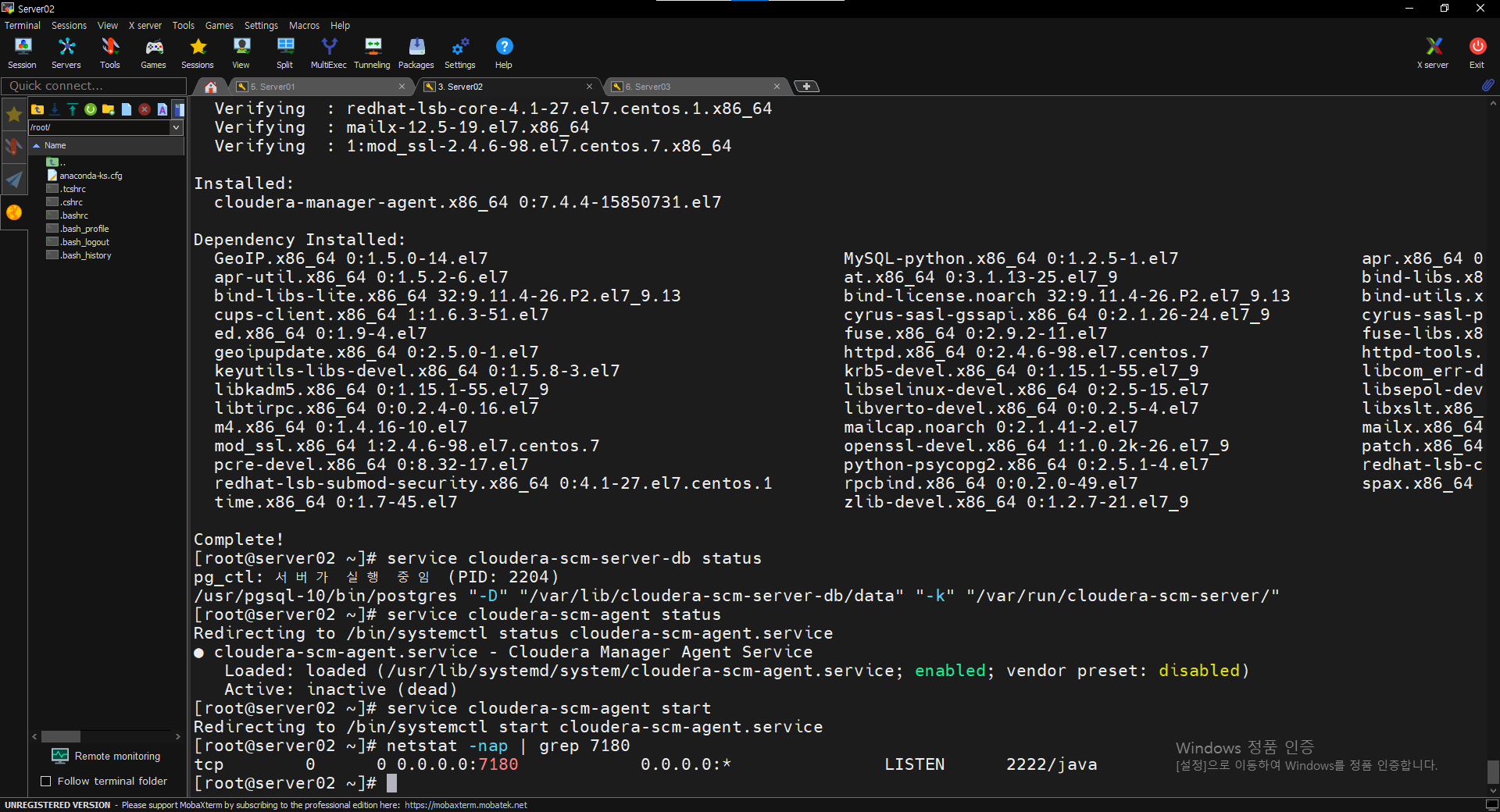
$ vi /var/lib/cloudera-scm-server-db/data/pg_hba.conf
=> 맨 아래에서 세번째 수정
=> host all cloudera-scm,scm 0.0.0.0/0 md5
=> 맨 아래 추가
=> host all all 0.0.0.0/0 trust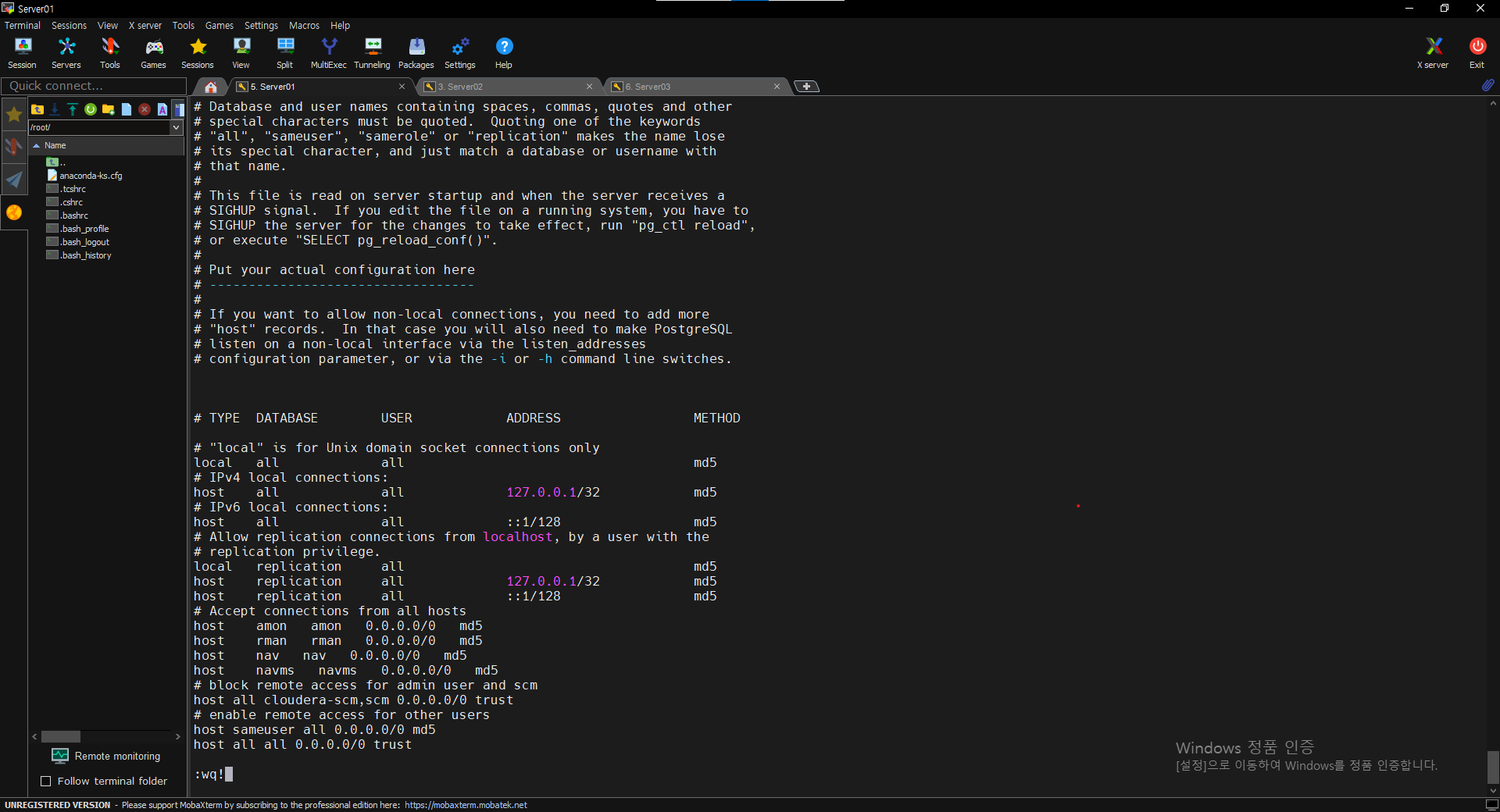
C:\Windows\System32\drivers\etc 안의 hosts 파일 내부에 추가
192.168.56.101 server01.hadoop.com
192.168.56.102 server02.hadoop.com
192.168.56.103 server03.hadoop.com
접속
http://server01.hadoop.com:7180/

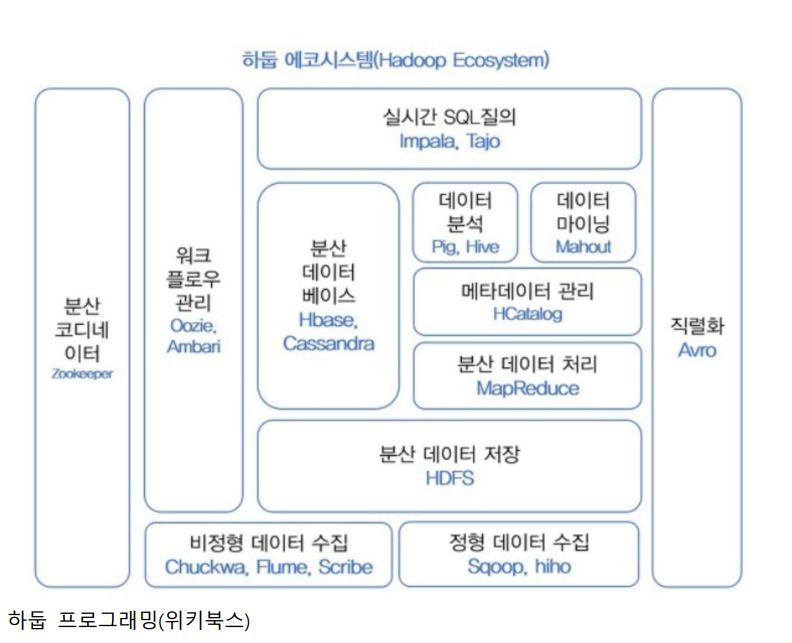
Hadoop 기초정리
p372
가상서버 메모리에서 돌아가 느려
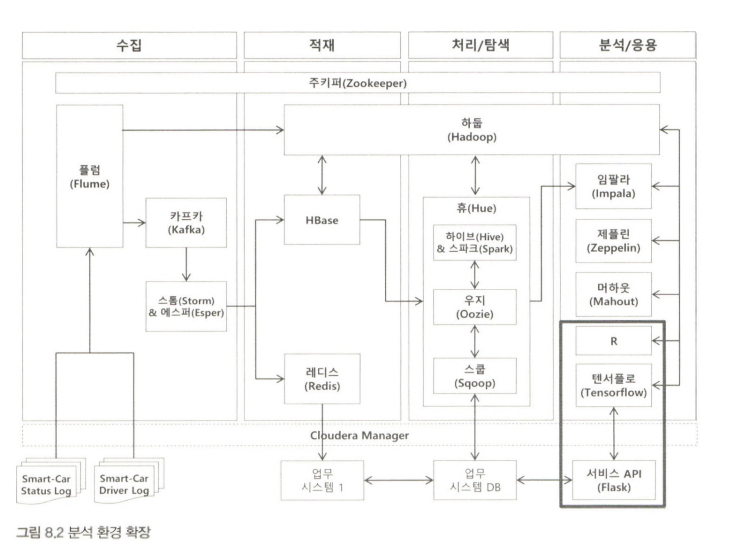
수집 적재 처리까지가 Hadoop
데이터를 어떻게 저장하고 저장했을 때 어떻게 잘 처리할지에 대한 부분을 하둡담당
(Hadoop을 공부한다고 java를 다 공부할 필요는 x Collection - ArrayList)
(Interface_)
HDFS과 맵리듀스 프레임워크로 시작
결과를 바탕으로 분석하고 결과를 표현하게 된다 => R, 텐서, flask
서비스를 해주는 건 flask
HadoopFileSystem
쪼개 저장해 -> (쪼갠것만 있으면 의미 없어 => NameNode가)
물리적인 저장소
백업
파이프
전반적인 운영을 해주는 게 HDFS
하둡의 동작흐름
데이터가 들어오면, 데이터를 쪼갠다. 그리고 그 데이터를 분리해서 저장한다.
따라서 데이터를 쪼갠 후에 어느 데이터 노드에 저장이 되어 있는지를 기록해 놓는 부분(메타데이터)이 필요하다.
정리하면, 하둡에서 데이터를 저장하기 전에 네임노드에서 분산을 하고 저장위치를 분배한다.
그 후에 여러개 중에 지정된 데이터 노드에 저장을 한다
분산저장의 경우네임노드(name node)와데이터노드(data node)로 나누어 처리된다. 이때 네임노드는 블록정보를 가지고 있는 메타데이터와 데이터 노드를 관리한다. 데이터노드는 데이터를 블록단위로 저장하면서 블록단위 데 이터를 복제하여 데이터 유실에 대비한다.
병렬처리는잡트래커(JobTracker)와태스크트래커(TaskTracker)가 담당한다. 잡트래커는 전체 진행상황을 관리하고 자 원관리도 처리합니다. 테스크트래커는 실제 작업을 처리하는 일을 합니다. 이때 병렬처리의 작업단위는 슬롯으로 맵 슬롯과 리듀스 슬롯이 있습니다. 병렬처리를 통해 클러스트당 최대 4000개의 노드를 등록가능합니다.
네임노드
데이터노드
잡트래커
태스크트래커
최종프로젝트 시
잡트래커... 잡스케줄...
주제
팀원 - 맡은 역할
스케줄
흐름설계
트러블 슈팅(발생일시, 처리자, 등등)

일을 처리 => MapReduce
메타데이터를 보관 => HDFS
MapReduce는 일을 어떻게 나눠서 수행하는지를 Master에서 관리하고,
HDFS는 저장 시 어떻게 분산 저장할 지 를 Master에서 관리한다
HDFS 파일을 쪼개서 저장하겠다
Zookeeper 서버가 분리되어 있다
Zookeeper(사육사)는 이름에서 그 역할을 쉽게 짐작할 수 있다. 분산 시스템 간의 정보 공유 및 상태 체크, 동기화를 처리하는 프레임워크로 이러한 시스템을 코디네이션 서비 스 시스템이라고
'MLOps 개발자 양성과정 > bigdata' 카테고리의 다른 글
| [Day-86] (0) | 2023.04.26 |
|---|---|
| [Day-84] (0) | 2023.04.24 |
| [Day-81] 빅데이터 이해하기/파일럿 프로젝트 (0) | 2023.04.18 |


